本記事のPDF版はこちら
Ocean Coast by Maurice Denis、パブリック・ドメイン・マーク、スウェーデン国立美術館
はじめに
本ガイドラインは、デジタル化されたパブリックドメインの文化遺産資料の利用に関して、それを所蔵する文化遺産所蔵機関が自身への言及を利用者に促したい場合のデザイン上のアイディアと実施例を提供するものです。本ガイドラインはパブリックドメイン資料をオープンに共有する所蔵機関を対象としていますが、文化遺産の電子資料に関連する著作権ライセンス問題に関心のあるすべての人にとって有益であると考えます。
背景
オープンカルチャーの広まり
文化遺産所蔵機関は、所蔵する資料を保存し共有することで、地域社会にとって欠かすことのできない役割を担っています。そしてインターネットとそれに伴うデジタル革命によって、所蔵機関が相次いで収蔵品をオンラインで公開し始めました。つまり、著作権の制約がない、またはほとんどない状態で、無料でアクセス、利用、再利用できるように広く公開されるようになったのです。クリエイティブ・コモンズの「Open Culture Voices 」シリーズで多くの専門家が述べているように、オープン化は地域社会や一般市民に対して計り知れないほどの恩恵をもたらします。クリエイティブ・コモンズ(CC)ライセンス とパブリック・ドメイン・ツール は、「オープン」を実現するための重要な要素です。
パブリックドメイン作品のデジタル複製を公開するときに使えるCCライセンスはない
デジタル化され、オンラインで利用できるようになった多くの文化遺産は、著作権の保護期間を過ぎている、あるいはそもそも保護されていなかったパブリックドメインのものであり、著作権の許諾なく、誰でもどのような目的でも利用することができます。CCでは、パブリックドメイン作品の忠実なデジタル複製は、パブリックドメインとすべき であり、新たな著作権や関連する権利を生じさせてはならないと強く主張しています(和訳版はこちら )。同じ文脈で、ライセンスは著作権で保護されているコンテンツに関してのみ使用できるものであるため、パブリックドメイン作品のデジタル複製物を公開する際にCCライセンスを使用することはできません。それらを共有するには、現在、パブリックドメインに置くためのツール(CC0)の利用を推奨しています。
広く実践されているが問題のある「PD BY」
しかしながら、非常に多くの所蔵機関がCC0ではないCCライセンスを使って、パブリックドメイン資料の忠実な複製を公開しています。これは「PD BY」とも呼ばれることがあります。なぜこのようなことが広まったのでしょうか?それは、多くの所蔵機関が、文化遺産を保存、修復、デジタル化、共有しているのが自分たちであることを周知したいと考えているためです。そしてこれらの所蔵機関は利用者にクレジットを表記することを求める手段としてCCライセンスを使用しているのです。一方でCC0は帰属の表示を義務付けていません。私たちが作成した「 Needs Assessment Report: Are the Creative Commons Public Domain Tools Fit-for-Purpose in the Cultural Heritage Sector? 」の資料でも、アンケートに回答した所蔵機関の約53%が、利用者にクレジット表記をしてもらう方法を求めていると答えており、素材が再利用・共有される際に所蔵機関がクレジット表記を受ける方法が無いことが、CC0で足りていない主なニーズであることが明らかになっています。
パブリックドメイン資料のより良い共有方法について 先住民の文化遺産をオープンに共有することに関連して述べた ように、対象物の著作権の状態は、正当な所有権や管理者を決定することはもってのほか、アクセスや利用の可能性を決定する唯一の方法では決してありません。
Sharing Public Domain Collections CC-BY ?!!? by Brigitte Vézina は “The Scream ” をリミックスしたものです。本作品はCC BY 4.0のもとで提供されています。The Scream ” Edvard Munch (1893), Public Domain, National Museum Oslo
管理している所蔵機関をCCライセンスで参照するのは
私たちは、所蔵機関が自分たちのコレクションからのパブリックドメインのデジタルなオブジェクトが利用される際に、自分たちが言及されること望むことに概ね共感しており、功績を認めるべき内容についてはユーザーはそのことをクレジット表記するべきだ と考えます。しかし私たちは、実際にそれを行う手段としてCCライセンスを使用することに、以下の4つの主な理由から強く反対します:
資料の著作権状態が不明確になってしまう
資料へのアクセスや利用条件について利用者に混乱と誤解が生じる
ライセンスが無効となり法的強制力がない状況を作り出してしまう
CCの帰属表示ガイドライン とライセンス表記 では、著作物のタイトル、作者または作成者、ライセンス、および出典(通常はURL)のみの記載を要求しているため、必ずしも所蔵機関の記載につながるとは限らない
所蔵機関は何をすべきか?
2022年、Deborah De Angelis(CC Italy )と渡辺智暁(CC Japan )が率いる CC Open Culture Platform のワーキンググループは、この問題を詳細に調査し「PD BY 」の問題に対処するための技術的、法的、社会的介入に関する提案 を作成しました。
そしてワーキンググループの挙げた社会的介入策に触発され、私たちは、オープンライセンスまたはパブリックドメインの資料を利用する人々が資料を提供している所蔵機関に言及することを簡単かつ魅力的にするために、所蔵機関が導入できるシンプルなデザインアイデアを開発しました。Behavioural Insights Team の EASTモデル (「ナッジ」によって行動変容を起こしたり、特定の結果を促したりするためのシンプルなフレームワーク)を使って、適切な場面で所蔵機関が包括的な「典拠ステートメント」を提供するためのいくつかの方法を提案します。これらのユーザー・エクスペリエンスに関するアイデアは、CCライセンスやその他ツールと組み合わせて使用することができます。提案する機能の実装方法に関するHTML/CSSコードを含む技術的なガイドラインは提供しませんが、このリソースが各所蔵機関の技術環境に実装可能なデザインの青写真となることを願っています。
所蔵機関のためのクリエイティブ・コモンズの
どのような情報を含めるべきか?
適切なステートメントには、以下の情報を含めるべきです:
タイトル
著者または作成者
ライセンスまたは許諾
所蔵機関
出典
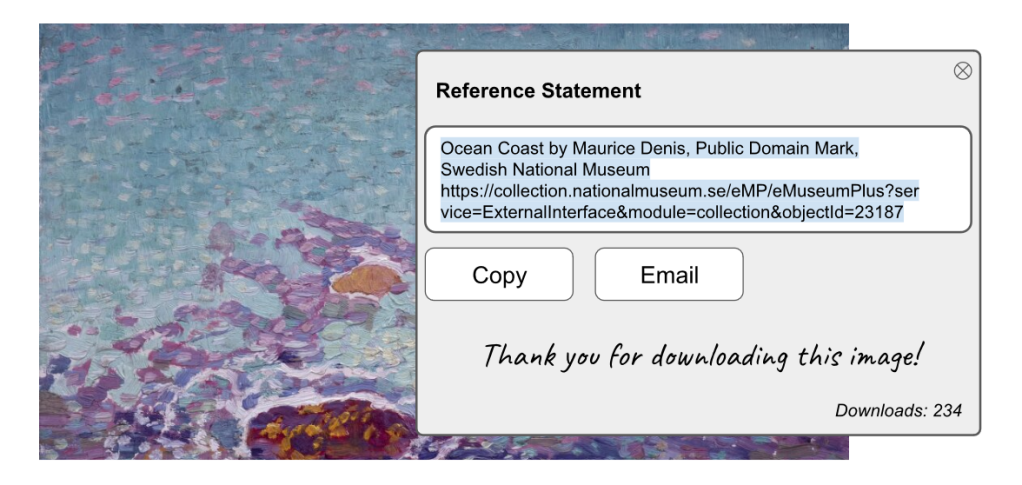
こちらはその例です:
Ocean Coast by Maurice Denis、パブリック・ドメイン・マーク、スウェーデン国立美術館https://collection.nationalmuseum.se/eMP/eMuseumPlus?service=ExternalInterface&module=collection&objectId=23187
所蔵機関はどのようにユーザーを促すことができるか?
所蔵機関は Behavioral Insights Team の EASTモデルを使って、ユーザーを誘導したり言及を促すことができます:
Easy(簡単) – 人々が参照しやすいようにする。
Attractive(魅力的) – 人々がやりたくなるようなものにする。
Social(社会的) – 行動を社会的価値につなげる。
Timely(タイムリー) – 適切なタイミングで情報を提供する。
所蔵機関がEASTモデル を適用するための簡単で戦略的な方法をまとめると以下ようになります:
Easy(簡単)にする方法
ワンクリックで参照先をコピーできるようにする
参考文献のテキストを自動ハイライトする
Attractive(魅力的)にする方法
資料を使ってくれることに感謝の意を述べる
ユーザーにとって情報をわかりやすく提供する
すべての情報を同時に提供する
Social(社会的)にする方法
ダウンロード数の共有
参照情報のコピー回数の共有
適切な参考文献の例を示す
ユーザーにソーシャルメディア上で機関のタグ付けを促す
出典を示すことで信頼を築く
Timely(タイムリー)にする方法
資料がダウンロードされたときにポップアップを表示する
ダウンロードしたファイルと一緒に参照情報を提供する
参照情報をメールで送信する
ユーザーアカウントを提供し、ユーザーが自身のダウンロード履歴を見られるようにする
実際にナッジの実装例を見てみましょう
このセクションでは、これらの戦略が実際にどのように実装されるか、4つのデザイン案を提示します:
コピーボタン
自動ポップアップ
テキストファイルをダウンロードするオプション
ダウンロード履歴が参照できるユーザープロフィール
典拠ステートメントを簡単にコピーできるボタン
ポップアップで典拠ステートメントを表示
資料と一緒にテキストファイルをダウンロードする
ダウンロード履歴が残るユーザープロフィール
設計のためのデータ整理
このセクションでは、(すべて JSON-LD で動作する)限定的なフレームワークと、典拠ステートメントを含めるのに適した構造を提供するプラットフォームの例を挙げます。
JSON-LD とは? JSON-LD は軽量のリンクトデータ 形式です。リンクトデータとはウェブサイト間で標準ベースの機械可読データのネットワークを構築する方法で、ウェブ上で情報を公開したり利用したりすることを可能にします。JSON-LD は人が読み書きしやすく、すでに成功している JSON フォーマットをベースにしています。JSON-LD は、JSON データをウェブのスケールで相互運用するための方法を提供します。JSON-LD は以下のプラットフォームの例に共通する標準であり、主要な検索エンジンによって推奨され、Internationalized Resource Identifier(RDI) を使用しています。
データフレームワーク
Schema.org の 「CreativeWork」
Schema.org は、インターネット上の構造化データのためのスキーマを作成し、維持し、普及させることをミッションとする共同的なコミュニティによる活動です。スキーマは「タイプ」の集合であり、それぞれが項目の集合に関連付けられ、階層構造になっています。検索エンジンの発見性を高めるための最良の選択肢です。
CreativeWork のタイプには、以下のような数多くの項目があります:
名前(タイトル)
著者および作成者
ライセンスと構造化データライセンス
発行者
URL
著作権表示とクレジット
これらの項目は、コレクションのデータを標準化された機械可読な方法で構造化することを可能にします。入力データは、別の項目、例えば著作権表示やクレジットの項目を入力するために使用できます。
IIIF の 「requiredStatement」
International Image Interoperability Framework(IIIF) は、コレクション管理のための世界標準であり、世界中の文化遺産機関で広く利用されています。
IIIFの 「requiredStatement 」は、資料が表示または利用される際に表示する必要があるテキストです。例えば、著作権や所有権に関する記述、所有機関や公開した機関への言及、そのほか利用者に表示することが重要であると判断されるテキストを何であれ提供することができます。
IIIFの権利表明のための「クックブック 」は、ソースコードのガイドラインと実装方法を提供しています。
クリエイティブ・コモンズは所蔵機関に対し、利用者に参照してもらいたいすべての情報を「requiredStatement」に含めることを推奨しています。これには、タイトル、作成者または作者、提供機関名、著作権の状態、使用されているライセンスまたはパブリックドメインツール、出典が含まれます。
ccREL について The Creative Commons Rights Expression Language(ccREL) は、著作権のライセンス条項や関連情報を機械可読的に表現するためのクリエイティブ・コモンズの標準です。ccRELは、World Wide Web Consortium の Resource Description Framework(RDF)に基づいています。2008年に提案されましたが、それ以来この標準への支持は著しく減少しています。現在は検索エンジンでの発見性向上のために ccREL を使用することは推奨されていません。検索エンジンでの発見性向上のためには Schema.org の 「CreativeWork 」の使用をお勧めします。
共有のためのプラットフォーム
所蔵機関が所蔵するデジタル・オブジェクトを共有するためのプラットフォームは数多く存在します。ここでは、このガイドラインで提示されているデザインアイデアの一部をすでに実装している2つのプラットフォームを紹介します。
Europeana
Europeana は、ヨーロッパの文化遺産コレクションの統合プラットフォームです。公開されている API やその他のツールを使用してデジタルコレクションに関する情報を収集し、ヨーロッパのデジタル化されたコレクションへのアクセスと要覧を世界に提供しています。
このプラットフォームは、ユーザーが資料をダウンロードする際にステートメントを提供します。このステートメントには提供機関からの情報が入力され、Europeana への投稿に最低限必要なメタデータ の一部となります。現在は提供機関へのレファレンスが含まれるようになっています。ステートメントは以下のフォーマットに従っています:
[タイトル] by [作成者] – [年] – [提供者], [国] – [権利に関するステートメント]
ウィキメディア・コモンズ
ウィキメディア・コモンズ は、ウィキメディアが提供する画像、音声、動画を含むメディアファイルのコレクションです。アップロード者が資料のメタデータに帰属表示情報を追加した場合、その情報が利用者に対して表示されます。帰属表示に関する情報 はメタデータ情報に書き込むことができ、資料のタイトル、作成者、出版機関、著作権ライセンスまたはパブリックドメインツールの情報を入力することができます。これは 「Other fields = {{Credit line}} 」のセクションに含めるのがベストです。
追加のサポート
これらのデザインのいずれかを実装する予定はありますか?このガイドラインを発展・改善させる方法(特に技術的な面で)についてご意見はありますか?この資料を他の言語で提供したいですか?
その場合は:
謝辞
このガイドラインは、オープン・カルチャー・コーディネーターの Connor Benedict とクリエイティブ・コモンズの政策・オープン・カルチャー担当ディレクターの Brigitte Vézina によって作成されました。また本ガイドラインの作成にあたって、 Deborah De Angelis (CCイタリア)と渡辺智暁(CCジャパン)が率いるオープン・カルチャー・プラットフォーム のワーキンググループのメンバーや、他のクリエイティブ・コモンズコミュニティのメンバー、クリエイティブ・コモンズのスタッフからの有益なフィードバックを受けることができましたことを深く感謝します。
画像のクレジット
その他のクレジット
本資料は Creative Commons による “NUDGING USERS TO REFERENCE INSTITUTIONS WHEN USING PUBLIC DOMAIN MATERIALS ” を翻訳したものです。
元の資料のライセンス表示:Creative Commons 2024 | Creative Commons Attribution License 4.0 (CC BY 4.0)
本資料はクリエイティブ・コモンズ 表示 4.0 ライセンスの下に提供されています。
翻訳に際して DeepL の出力を参考にしました。








{kind=link}
{kind=link}